A Practical Intro to Deep Learning
This content is intended to provide a very broad introduction to deep learning for a general audience. Full disclaimer here.
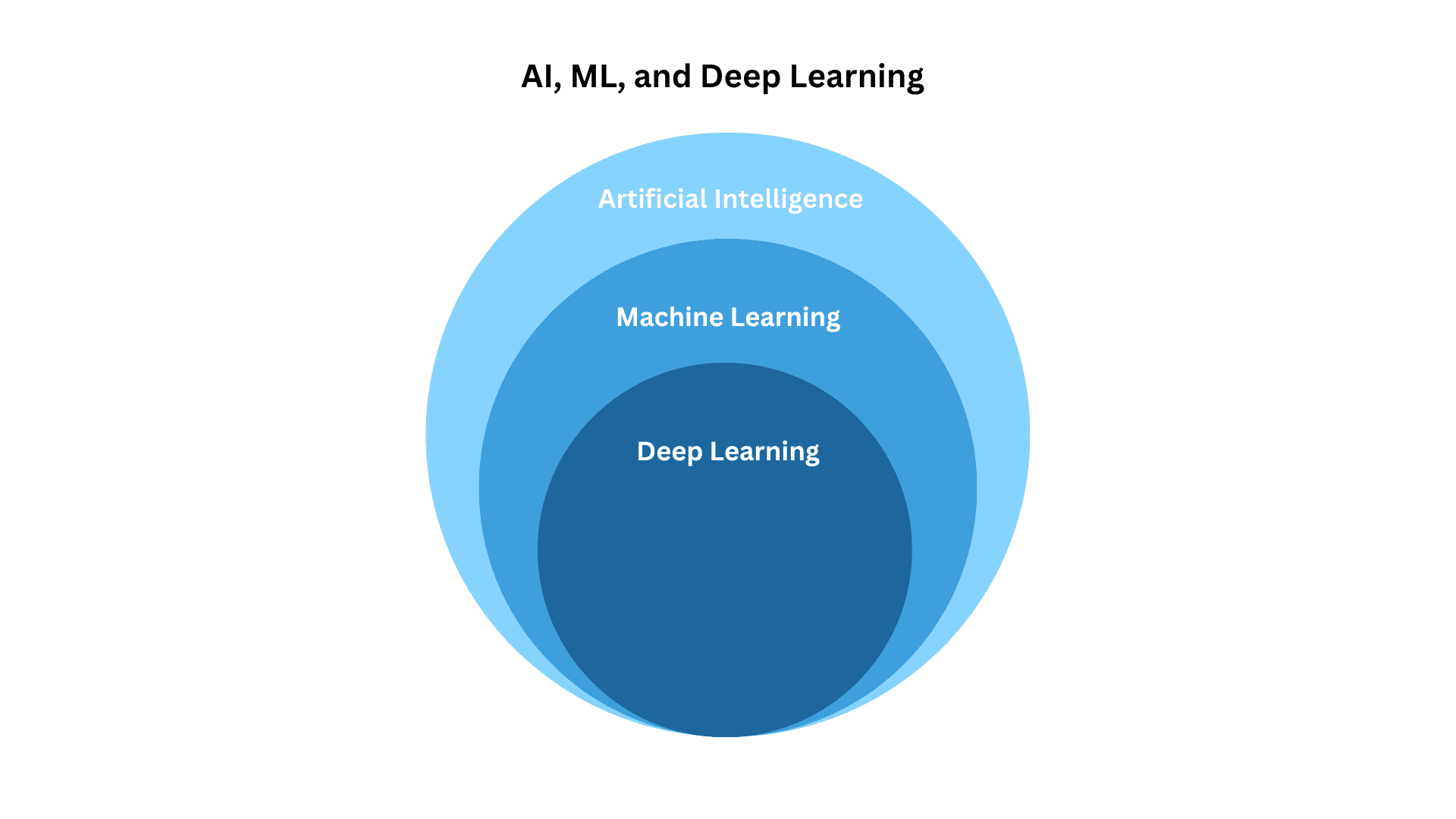
What is deep learning?
Deep learning is an advanced machine learning techniqueMethods or algorithms used by computers to learn from data and make predictions or decisions. that enables computers to perform complex tasks such as natural language processing, computer vision, and speech recognition[1][2].
What are neural networks?
-
Deep learning utilizes neural networks to process and learn patterns from unstructured dataUnstructured data is information that lacks a predefined format, making it difficult to store, search, and analyze using traditional databases. Examples include text, image, audio, and video files.[2].
-
In neural networks, a series of layers is used to transform data via interconnected network nodes commonly referred to as "neurons" [3].
- Input: Receives the raw data or features to be processed by the network.
- Hidden: A series of mathematical operations that learn complex features in the data.
- Output: Produces the final results based on the learned representations from the hidden layers.

- Encoder-decoder architectures convert unstructured data (text, images, audio) into latent representations for processing and back into human-readable forms[2].
How does it work?
To demonstrate how neural networks work, it helps to look at a classic first example in deep learning: classifying hand-written digits.
Task: Label millions of hand-written digits
There are a million image files, each representing hand-written digits from 0-9, and the task is to label each one of these images with the actual number shown.



How would you go about doing this? Would you do this by hand, or is there a better alternative? What if you needed to label 100 million images?
Solution: Build a deep learning classifier
With deep learning, the entire image set does not need labeling. Instead, a portion (30%, for example) can be labeled and a deep learning model can be trained to label the rest.

The online platforms you see today - ChatGPT, DeepSeek, Gemini - have already performed this task and provide out-of-the-box solutions.
Explained: How is the neural network trained?
A very broad overview of the training process is described below.
Step 1: Select images for model training
Images should be selected to represent the broader population, as biased training data will lead to a biased model.
Step 2: Prepare image data
To prepare data for the neural network, images are flattened from a 2-D square of pixels (ex. 256x256) to a 1-D column of pixels (ex. 65536x1).

In the example above, this would mean 65,536 neurons in the input layer - one for each pixel.
Step 3: Train the model
This is where the neural network uses an algorithm to learn patterns in the data.
The goal of the algorithm is to find model weights that minimize errors between model predictions (ex. 9) and the actual hand-written digits.
Step 4: Use the model
Once the model is trained on this initial data, you can then use it to label an additional million, 50 million, etc. images. You can also now measure the model accuracy, and use this as a benchmark to improve upon.
Why don't simpler techniques work?
Traditional machine learning models, such as linear regression and random forests, struggle with unstructured data because they rely on handcrafted features and do not scale well to high-dimensional inputs (e.g., pixels in images).
Image recognition requires capturing complex patterns and hierarchical relationships, which deep neural networks achieve by learning abstract features at multiple layers. This is where it gets the name Deep Learning[1].
Pretty deep, right?